
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- modal
- 개발자
- alamofire
- charts
- 라이브러리
- 어플리케이션
- ios
- graph
- Swift
- Android
- button
- Storyboard
- UITableView
- TableView
- 그래프
- Chart
- Python
- ui
- PyQt
- UIButton
- UIKit
- Chrats
- androidstudio
- 개발
- library
- PyQt5
- kotlin
- Xcode
- cocoapods
- Apple
- Today
- Total
Jiwift
[iOS/Swift] Swift OCR SwiftyTesseract를 이용한 글자 인식(Text Recognition) 본문
[iOS/Swift] Swift OCR - SwiftyTesseract
iOS Swift 환경에서 OCR을 적용해보려고 합니다. 정확한 이해보다는 실행에 중점을 두고 진행하겠습니다. 사용할 라이브러리 이름은 SwiftyTesseract입니다.
진행 순서
1. 소개
2. 설치
3. 간단 사용법
4. traineddata 추가
5. 결과
GitHub - SwiftyTesseract/SwiftyTesseract: A Swift wrapper around Tesseract for use in iOS, macOS, and Linux applications
A Swift wrapper around Tesseract for use in iOS, macOS, and Linux applications - GitHub - SwiftyTesseract/SwiftyTesseract: A Swift wrapper around Tesseract for use in iOS, macOS, and Linux applicat...
github.com

작동하는 다른 라이브러리들에 비해서 Star가 적은 모습을 보여주고 있습니다. 그래도 우리는 무료로 동작하는 라이브러리가 필요하니 일단 돌아가면 절하면서 사용해야 합니다.
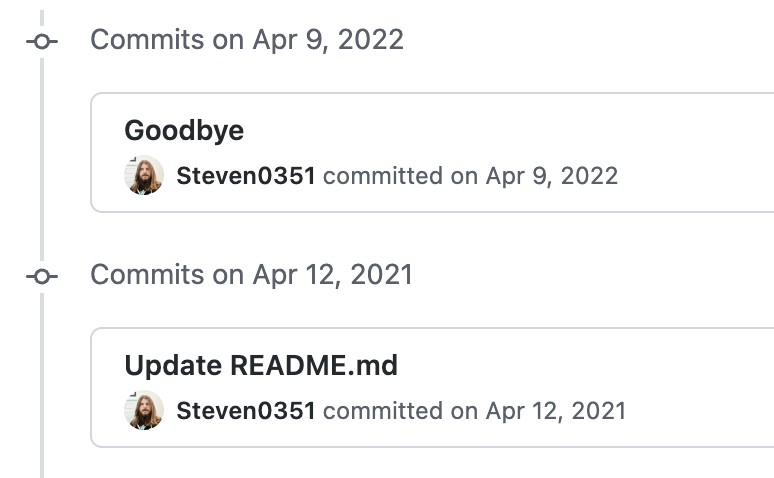
마지막 commit 이력은 Goodbye입니다. 뭔가 아련하면서도 아쉬운 모습입니다. 저 커밋을 이후로 이 라이브러리는 공식 지원이 종료되었습니다.
다른 라이브러리들과 비교하면 비교적으로 최신이 마지막 업데이트라서 빌드 에러가 없을 것 같아서 좋아했지만 종료를 금방 했습니다.. 물론 이 프로젝트뿐만 아니라 다른 프로젝트들도 말만 안 했지 마지막 업데이트를 확인하면 돌아가는 게 신기할 정도입니다.

라이브러리가 지원하는 범위입니다.

설치하는 방법은 Swift Package Manager를 사용해야 합니다. git을 읽어보면 Cocoapods과 Carhage는 지원을 중단했다고 설명하고 있습니다.
SPM을 통한 설치 방법은 위 링크를 통해 확인 가능합니다.

저는 글 작성 기준으로 라이브러리 두 개가 추가되었습니다. 이제는 코드를 작성할 겁니다.
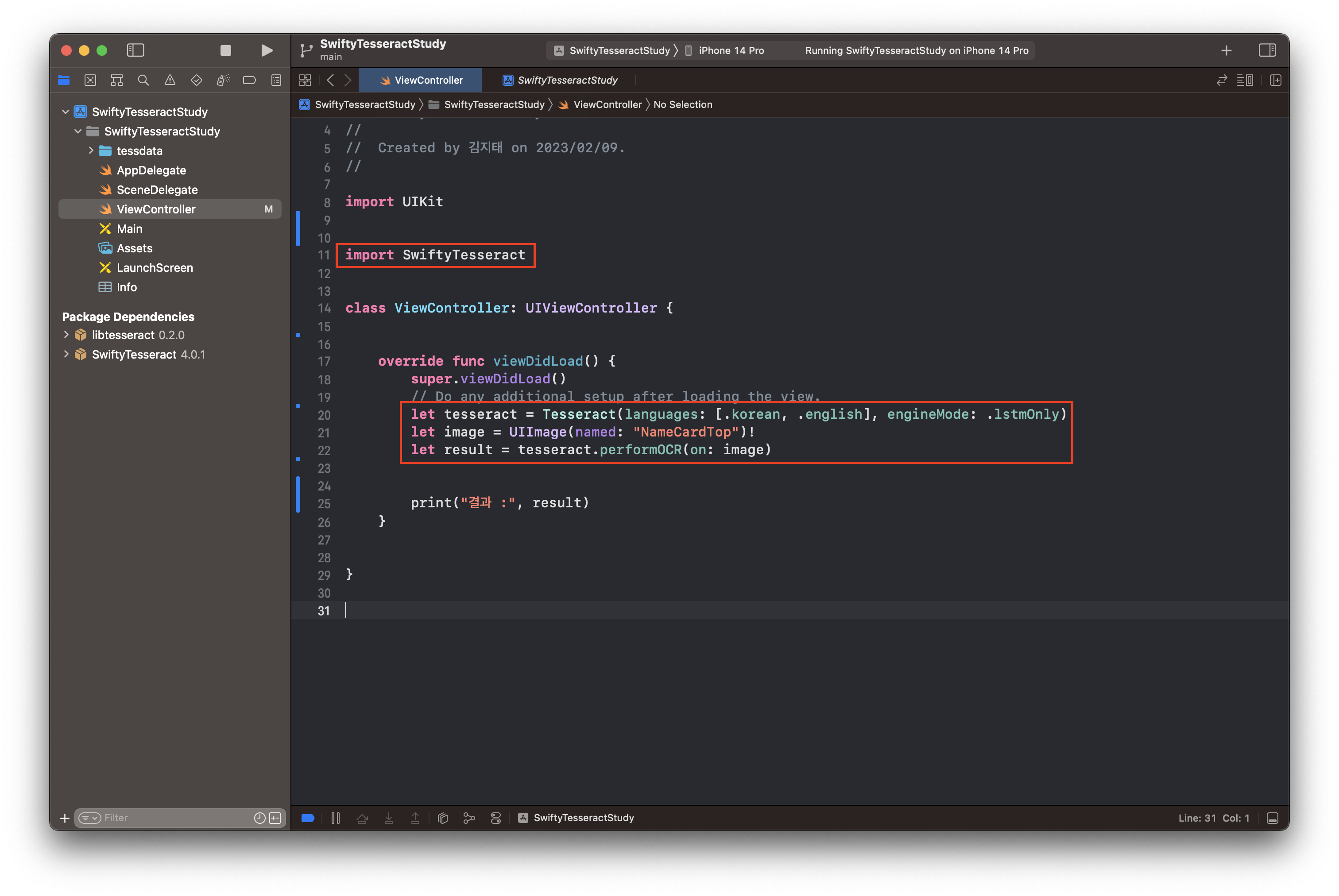
코드는 매우 간단합니다.
import SwiftyTesseract라이브러리를 먼저 import 하고
// 라이브러리 설정
let tesseract = Tesseract(languages: [.korean, .english], engineMode: .lstmOnly)
// 이미지 불러오기
let image = UIImage(named: "NameCardTop")!
// 이미지 적용
let result = tesseract.performOCR(on: image)
// 결과 확인
print("결과 :", result)동작하는 코드를 작성하면 됩니다. 이미지 불러오기는 카메라로 찍은 이미지를 사용하거나 리소스를 사용해도 됩니다. 저는 테스트하기 위해서 명함 이미지를 구해서 리소스에 넣어두었습니다.
(코드 작성해도 아직 작동 안 합니다.)
코드를 먼저 보면 launages와 engineMode를 설정합니다. launages는 사용하고 싶은 언어를 추가해야 합니다.
// 단일 언어
let tesseract = Tesseract(language: .korean, engineMode: .lstmOnly)
// 단일 언어
let tesseract = Tesseract(language: [.korean], engineMode: .lstmOnly)
// 다중 언어
let tesseract = Tesseract(languages: [.korean, .english], engineMode: .lstmOnly)위와 같이 단일 언어와 다중 언어를 설정할 수 있는데 그냥 다중언어로 선택하고 하나만 입력해도 동작합니다. 언어 수 제한은 딱히 없어 보이는데 테스트를 진행하지는 않았습니다.
engineMode는 lstmOnly, default, tesseractLstmCombined, tesseractOnly로 총 4가지가 존재합니다.
이제 traineddata를 프로젝트에 추가해야 합니다. Tesseract 엔진이 미리 train 된 데이터를 사용한다고 합니다. Tesseract는 4.0 버전부터는 LSTM이 추가되어 같이 돌아간다고 합니다.
traineddata는 'traineddata'와 'traineddata_best'가 있습니다.
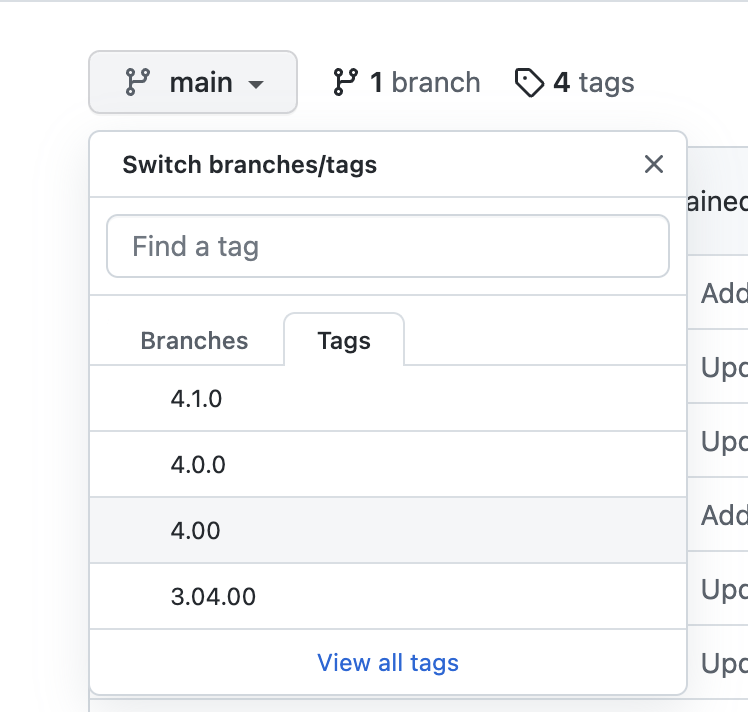
traineddata : 기본입니다. git에서 태그를 변경해서 3.x대부터 4.x대까지 선택 가능합니다.
traineddata_best : Tesseract 4.0에서만 지원한다고 나옵니다. 현재 Tesseract는 5.0까지 나왔는데 Swift에서 사용 가능한 라이브러리가 없어 테스트를 진행하지 못했습니다. 커밋 내용을 봤을 때 SwiftyTesseract는 4.x을 지원하는 것 같습니다. (정확한 버전을 알고 있으신 분은 알려주시면 감사하겠습니다.)
다운로드 링크
tesseract-ocr/tessdata: Trained models with support for legacy and LSTM OCR engine (github.com)
tesseract-ocr/tessdata_best: Best (most accurate) trained LSTM models. (github.com)
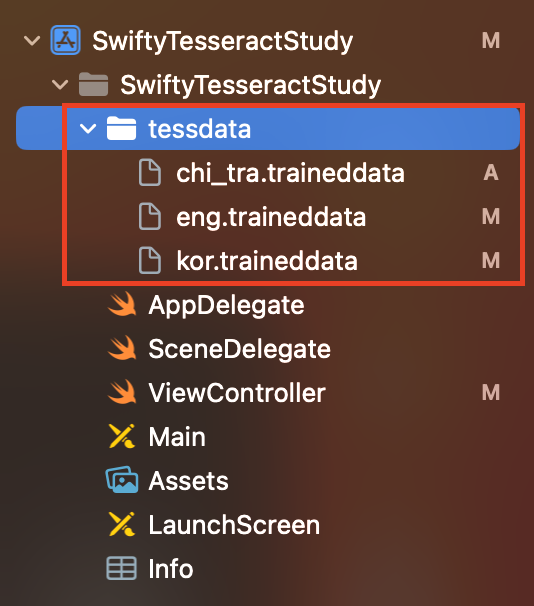
프로젝트 폴더 구성에 'tessdata'라는 폴더를 두고 그 안에 언어 데이터를 넣어야 합니다. 하지만 여기서 저는 약간 문제가 있던 게 폴더를 xcode에서 생성하고 언어 데이터를 이동시키면 인식이 안 되는 문제가 있었습니다.
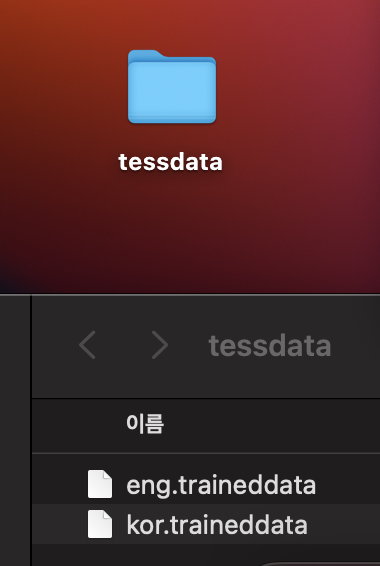
그래서 이렇게 외부에서 폴더를 만들어 그 안에 언어 데이터를 넣어두고 이동하는 방식을 사용했어야 했습니다.
(왜 그러는지는 모르겠는데,,, 이유를 아시는 분 있나요?)
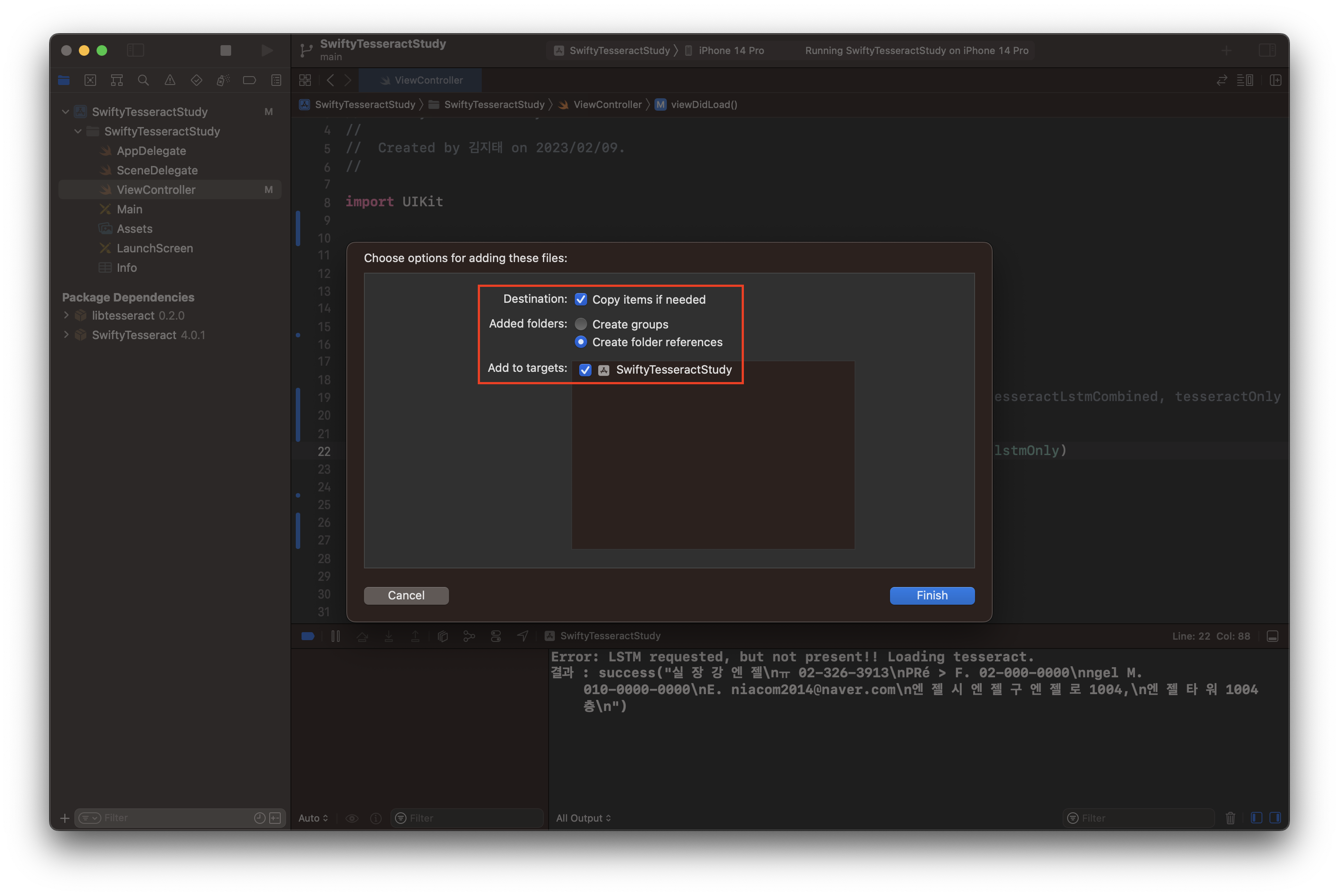
외부에서 생성한 tessdata 폴더를 넣을 땐 위와 같이 설정하고 넘겨야 합니다. 그냥 일본 애가 설명한 글에 이렇게 나와있길래 따라 하니 잘됩니다..
이제 원하는 언어를 코드로 설정하고 그 언어들 데이터까지 프로젝트에 넣어준다면 인식이 가능해집니다.

저는 인터넷에서 찾아 위 명함을 가지고 테스트를 진행했습니다.
우선 'traineddata', 'traineddata_best'를 같은 모드는 default로 두고 데이터 버전만 바꾸면서 실행한 결과입니다.
수행 시간은 위에서 소개한 코드에서 print을 제외한 3줄의 시간입니다.
1. traineddata 3.04.00
시간 : 약 1.1초
결과 : 실장 강엔젤\n1. 02426-391 3\nPR5 혼 r. oz—ooo-oooo\nngel M. m o-oooo—oooo\nE. niacom2014@naver.com\n엔첼시 앤첼구 앤출르 1004\'\n엔췌티워 1004충\n
2. traineddata 4.00
시간 : 약 0.96초
결과 : 실 장 강 엔 젤\nT.02—326—3913\nPRé o F. 02—000—0000\n09 이 M. 010—0000—0000\nE. niacom2014@naver.com\n인 젤 시 엔 젤 구 연 젤 로 1004,\n연 젤 타 워 1004 층\n
3-1. traineddata 4.0.0(chi_tra 데이터 없이)
시간 : 약 0.78초
결과 : 실 장 강 엔 젤\nㅠ 02-326-3913\nPRé > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔 젤 시 엔 젤 구 엔 젤 로 1004,\n엔 젤 타 워 1004 층\n
3-2. traineddata 4.0.0(chi_tra 데이터 있이)
시간 : 약 1.3초
결과 : 실 장 강 엔 젤\nㅠ 02-326-3913\nPRé > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔 젤 시 엔 젤 구 엔 젤 로 1004,\n엔 젤 타 워 1004 층\n
4-1. traineddata 4.1.0(chi_tra 데이터 없이)
시간 : 약 0.78초
결과 : 실 장 강 엔 젤\nㅠ 02-326-3913\nPRé > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔 젤 시 엔 젤 구 엔 젤 로 1004,\n엔 젤 타 워 1004 층\n
4-2. traineddata 4.1.0(chi_tra 데이터 있이)
시간 : 약 1.2초
결과 : 실 장 강 엔 젤\nㅠ 02-326-3913\nPRé > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔 젤 시 엔 젤 구 엔 젤 로 1004,\n엔 젤 타 워 1004 층\n
5. traineddata_best 4.0.0
시간 : 약 1.9초
결과 : 실장 강엔 젤\nT.02-326-3913\nPR: > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔젤시 엔젤구 엔젤로 1004,\n엔젤타워 1004충\n
6. traineddata_best 4.1.0
시간 : 약 1.9초
결과 : 실장 강엔 젤\nT.02-326-3913\nPR: > F. 02-000-0000\nngel M. 010-0000-0000\nE. niacom2014@naver.com\n엔젤시 엔젤구 엔젤로 1004,\n엔젤타워 1004충\n중간에 chi_tra 데이터는 잘 모르겠네요.. 없어도 결과는 나오는데 경고는 출력됩니다. 데이터 폴더에 찾으면 있으니 추가를 해주면 경고는 없어지고 실행 시간은 길어지지만 결과에 큰 변화는 없습니다.
역시 결과는 1번이 안 좋습니다. 전화번호를 잡아내지 못한 모습입니다.
'traineddata'에서 4.00을 제외하고는 결과가 좋고 같습니다. 하지만 '엔젤시', '엔젤구'와 같은 단어를 띄어쓰는 모습을 보여줍니다. 반면에 'traineddata_best'는 '엔젤시', '엔젤구'와 같은 단어를 붙여 쓰는 모습을 보여주면서 좋은 결과를 보여주었지만 시간이 약간 더 걸리고 중간에 공백이 어떤 이유에서인지 넓은 모습을 보여줍니다. (공백이 넓은 건 큰 문제가 안 돼 보이기는 합니다..) 'traineddata_best'에서 버전 차이는 없는 것 같습니다.
같은 engineMode에서는 traineddata_best가 시간은 좀 걸리지만 좋은 결과를 보여주었습니다.
또한 traineddata_best은 tesseractLstmCombined, tesseractOnly 모드가 작동하지 않았습니다.
참고
【iOS】オープンソースのOCRライブラリ「SwiftyTesseract」を試してみる - Qiita
【iOS】オープンソースのOCRライブラリ「SwiftyTesseract」を試してみる - Qiita
背景 【iOS】オープンソースのOCRライブラリ調査の続きです。 前回の調査の過程で、Tesseract OCR iOSとSwiftOCRの2つがGitHubのスター数から見ても人気だということが分かりました。しかしながら、
qiita.com
'라이브러리 > 기타' 카테고리의 다른 글
| [iOS/Swift] GCDWebServer 아이폰으로 웹 서버 열기 (0) | 2023.11.09 |
|---|---|
| [iOS/Swift] FSCalendar 최대 최소 선택 가능 날짜 지정 / Custom 달력 maximumDate minimumDate (0) | 2023.10.17 |
| [iOS/Swift] Swift OCR TesseractOCRiOS를 이용한 글자 인식(Text Recognition) (1) | 2023.02.11 |
| [iOS/Swift] Progress Bar Gradient / UIProgressView 프로그래스 바 그레디언트 색 주기, 둥글게 (0) | 2022.12.29 |
| [iOS/Swift] SkeletonView 사용법 - 기본 사용법 / 로딩 대기중 표현 (0) | 2022.11.10 |



