
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Android
- 라이브러리
- Storyboard
- modal
- Python
- button
- Chart
- PyQt
- UIKit
- UITableView
- 개발
- UIButton
- Xcode
- PyQt5
- graph
- TableView
- cocoapods
- charts
- ui
- 어플리케이션
- library
- alamofire
- androidstudio
- kotlin
- 그래프
- ios
- Chrats
- 개발자
- Apple
- Swift
- Today
- Total
Jiwift
RBPN - Recurrent Back-Projection Network for video Super-Resolution 본문
RBPN - Recurrent Back-Projection Network for video Super-Resolution
지위프트 2022. 12. 31. 12:00RBPN - Recurrent Back-Projection Network for video Super-Resolution
Recurrent Back-Projection Network for video Super-Resolution 논문 이해한대로 정리하기
저자 : Muhammad Haris, Greg Shakhnarovich, Norimichi Ukita
공개 : CVPR2019
논문 : rbpn_cvpr2019.pdf (alterzero.github.io)
Abstract
우리는 순환적인 인코더-디코더 모듈을 사용하여 연속적인 영상 프레임으로부터 spatial(공간) context와 temporal(시간적) context를 통합한다.
이 문장에서 시간적과 공간적은 처음에는 이해가 잘 가지 않았다. 하지만 논문을 읽다보면 motion flow, 다른 프레임에서 얻을 수 있는 정보, 그리고 시간적 정렬을 사용한다고 주장한다. 그래서 이해하기를 시간적 프레임에서 주변 프레임 정보를 얻어 공간적인(or 움직임?)을 통합해서 SR을 한다고 이해하기로 했다.
인코더-디코더 모듈을 반복적으로 사용하여 연속된 비디오 프레임에서 공간(spatial) 및 시간적(temporal) context를 통합하며
앞이랑 같은 내용이다. 논문에서 target frame은 시간적 순서대로 들어오고, 인접 frame을 가지고 motion flow(공간적 정보?)를 뽑는 작업이 있다. 구조적으로 두 작업은 따로 진행되어 나중에 통합이 되는데 그것을 뜻해보인다.
스택 또는 뒤틀림을 통해 프레임을 함께 풀링하는 대부분의 이전 작업과 달리, 우리의 모델인 RBPN(Recurrent Back-Projection Network)은 각 context frame을 별도의 정보 소스로 취급한다. 이러한 소스는 MISR의 “Back-Projection” 아이디어에서 영감을 받은 반복적인(iterative) 정제 프레임워크에 결합된다.
다시 한번 설명이다. 시간과 공간을 계산해서 합치고 feature 뽑는 동작을 진행하는 것이 아닌, 시간과 공간은 별도의 정보 소스로 존재하고 feature가 나오면 그 둘을 Back-Projection에서 결합한다는 내용으로 이해했다. (합치고 계산하느냐 계산하고 합치느냐?)
대충 이러한 방법으로 VSR(Video Super Resolution)을 진행한다고 한다.
Back-Projection = target image와 그에 해당하는 image set 사이의 error인 residual image를 반복적으로 계산 (residuals은 resolution을 향상시키기 위해 target image로 back-projection)
솔직히 무슨 말인지 이해가 안가지만 구조를 보면 projection module 속에 Encoder, Decoder가 나오는데 Encoder가 Back-Projection을 한다고 나온다. 그림과 함께 보도록 하자
Introduction
SR의 목표는 LR 이미지에 누락된 사항을 채워 낮은 해상도 이미지를 높은 해상도로 향상시키는 것이다. SR분야는 Single-Image SR, Multi-Image SR, Video SR로 나눌 수 있다. 논문은 VSR이 중점이다.


I(t-n)부터 I(t+n)까지의 LR Video frame이 있는데 그 중 target frame = I(t) 을 고화질로 개선하는 상황을 생각해보자.
말이 어렵긴한데 동영상을 생각하면 그냥 시간적 순서대로 프레임1, 프레임2(target frame), 프레임3 을 SR하는 상황이다.
SISR
장점 : 다른 프레임과 상관없이 독립적으로 화질을 개선할 수 있다.
단점 : 다른 프레임에서 얻을 수 있는 정보를 사용하지 못한다.
MISR
장점 : 다른 프레임이 가진 세부 정보를 target frame을 SR하기 위해 융합한다.
단점 : 프레임을 정렬하는 과정이 필요하지만 정렬은 어렵고 MISR은 independently하게 정렬되므로 정확하 정보를 얻기가 어렵다.
VSR
장점 : 최근의 VSR 방법에서는 시간적 순서의 따라서 Frame이 concatenated되거나, recurrent network에 적용된다.
단점 : Concatenated 방식은 많은 프레임이 동시에 처리되므로 학습에 어려움이 있다. Recurrent network 방식은 LSTM과 같은 긴 의존 기간을 유지하도록 설계해도 비디오의 모든 프레임에서 보이는 변화를 모델링하는 것이 쉽지 않다.
기존 SR 방식으로 영상을 SR했을 때를 설명해주고 있다.
SISR을 프레임을 다른 프레임과 상관없이 개선이 가능해서 간편하지만 연속성이 있는 영상에서는 주변 프레임의 장면 정보를 활용하지 못해 좋지 못하다고 한다. 이럴 경우 같은 영상이지만 프레임마다 다른 느낌의 SR이 이루어질 수 있기 때문이다.
MISR은 다른 프레임이 가진 세부 정보를 target frame SR을 위해 융합한다고 설명한다. 다른 프레임 정보를 추출하려면 프레임은 정렬되어야 한다. 하지만 Video Super-Resoultion을 위한 정렬은 정밀해 하며. MISR는 시간적 흐름이 아닌 independently하게 정렬되므로 정확한 정보를 얻기가 어렵다고 논문은 주장한다.
찾아본 결과 어느 블로그에서는 MISR은 한 장의 image에서는 얻을 수 없는 정보들을 다른 프레임에서 얻을 수 있다는 장점이 있다. 하지만 같은 scene의 image를 다른 시간이나 sensor로부터 얻기 때문에 많은 복잡한 사항들을 고려해줘야 한다는 단점이 있다고 한다.
Convolution network를 사용하는 최근의 VSR 방법에서는 시간적 순서의 따라서 frame이 concatenated되거나 recurrent network에 적용된다. 시간적으로 정렬이 된다면 기존 정렬들 보다 좋은 결과를 가지고 오지만 많은 문제가 있다. concatenation 접근 법은 많은 프레임이 network에서 동시에 처리되므로 학습에 어려움이 있고 RNN 방식에서는 LSTM과 같은 긴 의존 기간을 유지하도록 설계된 경우에도 비디오의 모든 프레임에서 관찰되는 미묘하고 중요한 변화를 공동으로 모델링하는 것이 쉽지 않다고 주장한다. 논문에서는 물체의 변화를 느리거나 빠른 움직임을 예로 들었다.
SISR = Single Image Super Resolution
MISR = Multi Image Super Resolution
VSR = Video Super Resolution
Realated Work
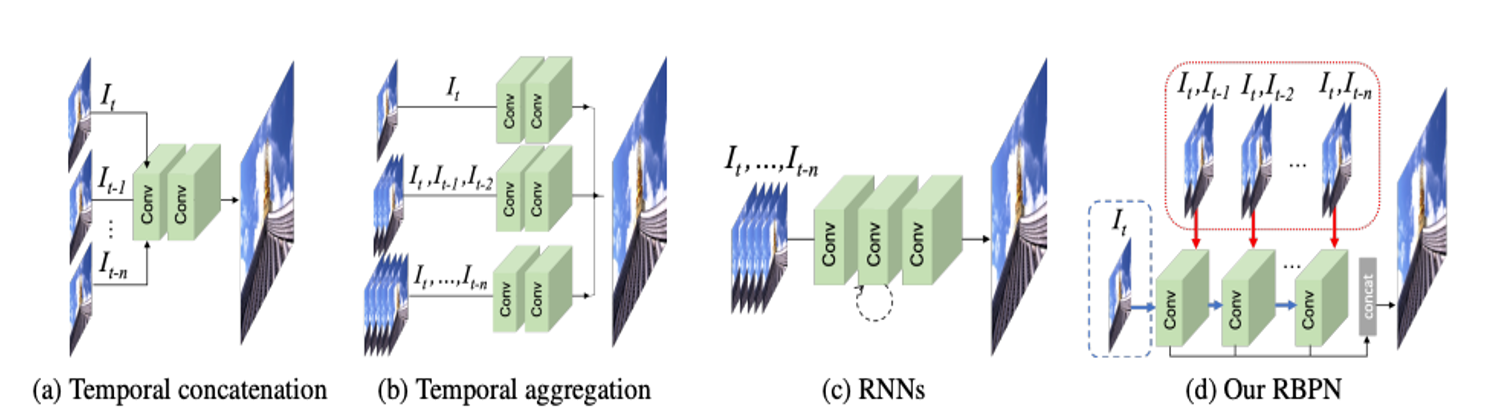
관련 연구 부분에서는 ‘2.3. Deep Video Super-resolution’ 부분만 보기로 했다.
위의 사진이 VSR의 방법들이라고 한다. 위 Introdution에 VSR 내용과 많이 겹친다.
(a) 방법은 가장 기본적이고 모든 프레임을 concatenation하니 학습하는데 어렵고 모션 regimes에 약하다고 한다.
(b) dynamic motion problem을 해결하기 위해 다양한 motion regimes에서 작동하는 multiple SR inferences (다중 SR 추론)이 제안되었다고 한다.
(c) RNN 방식은 네트워크 capacity(용량)가 작고 프레임 정렬이 필요 없다고 합니다. 하지만 앞 장에서 말했듯이 모든 프레임에서 관찰되는 미묘하고 중요한 변화를 공동으로 모델링하는 것이 쉽지 않고 주장합니다.
(a),(b) 두 방식은 많은 입력을 요구하므로 최적화가 어렵다. (c) 방법은 입력을 앞에 두 방법 보다는 적지만 다른 단점이 존재하는 것이 보인다.
Recurrent Back-Projection Networks
Network Architecture
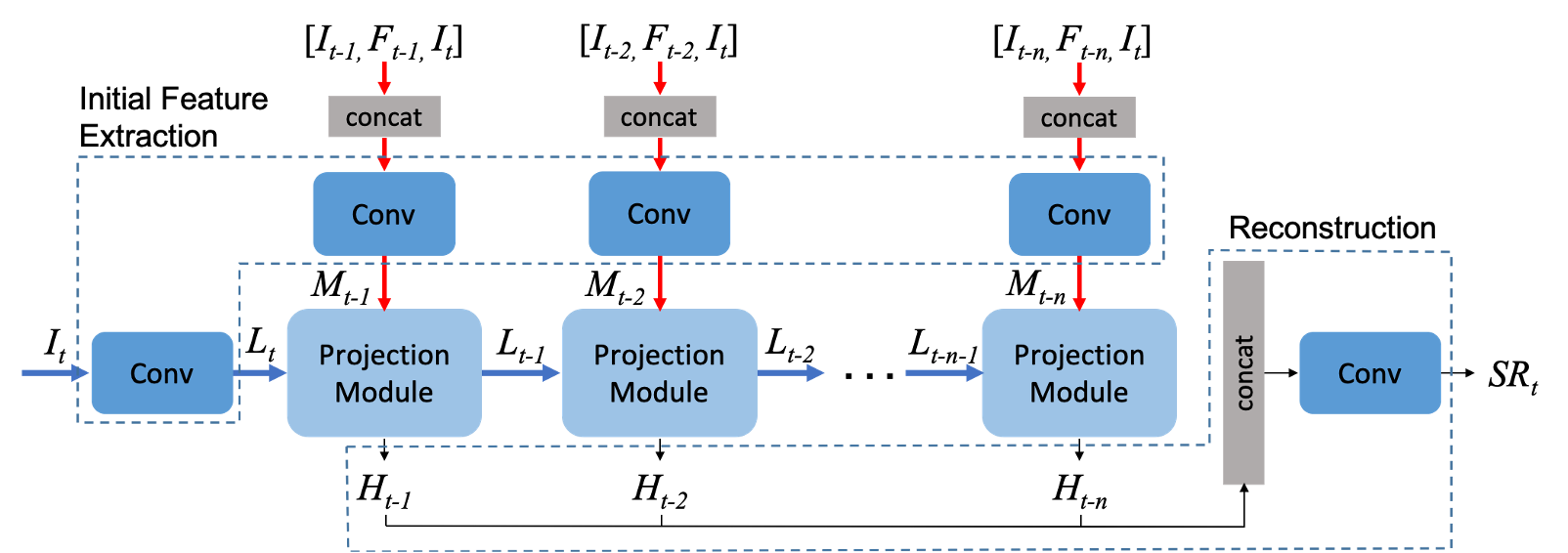
논문 저자들은 새로운 방식을 만들었는데 MISR에서 back-projection 그리고 그 방법에서 영감 받은 SISR에 Back-projection을 사용한 DBPN 방식을 합친 방법이라고 한다.
Back-Pojection = target image와 그에 해당하는 image set 사이의 error인 residual image를 반복적으로 계산 (residuals은 resolution을 향상시키기 위해 target image로 back-projection)
DBPN(SISR) = 한 장의 이미지를 가지고 업, 다운 샘플링을 반복해 HR feature를 정제한다. 이미지에 덧대어서 해상도를 높인다. (Convolution과 deconvolution을 반복)
https://blackchopin.github.io/sr/DBPN/
쉽게 말해서 MISR과 DBPN(SISR)을 합친 방법이다. 둘은 Multi Image와 Single Image로 나뉘지만 Back-Projection이라는 공통점이 있다.
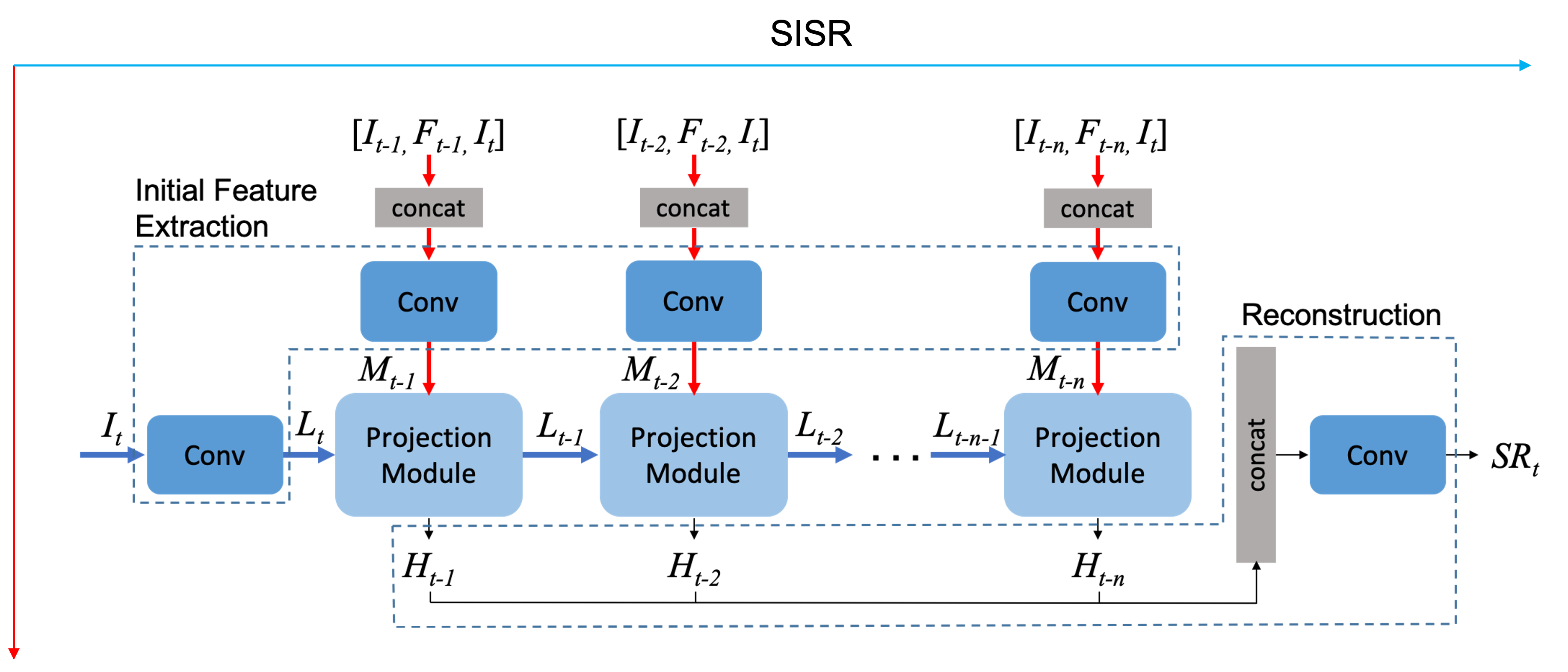
우선 RBPN의 진행 방향은 두 곳에서 들어와서 한곳으로 나가는 구조다. 파란색 진행은 SISR 진행, 빨간색 진행은 MISR 진행 두 진행은 projection module에서 만나고 있다.
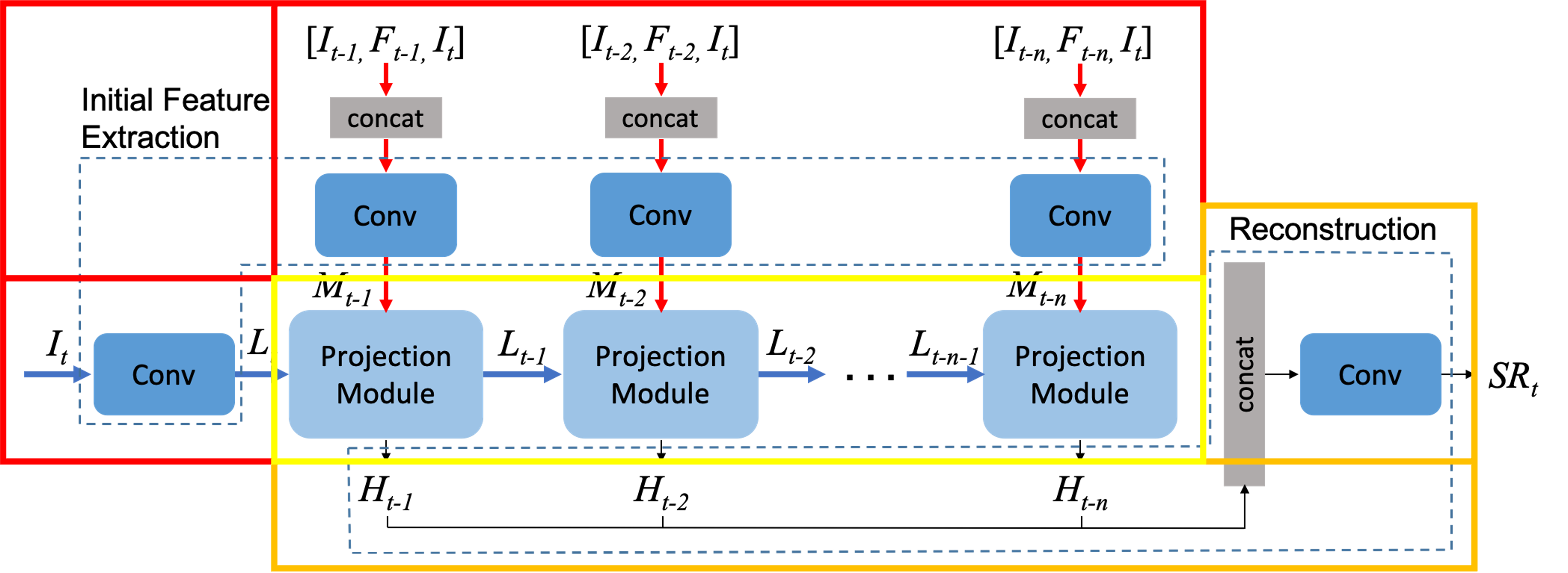
빨간색 박스 : 초기 feature 추출 단계
노란색 박스 : Multiple Projection 단계
주황색 박스 : Reconstruction 단계
초기 feature 추출 단계
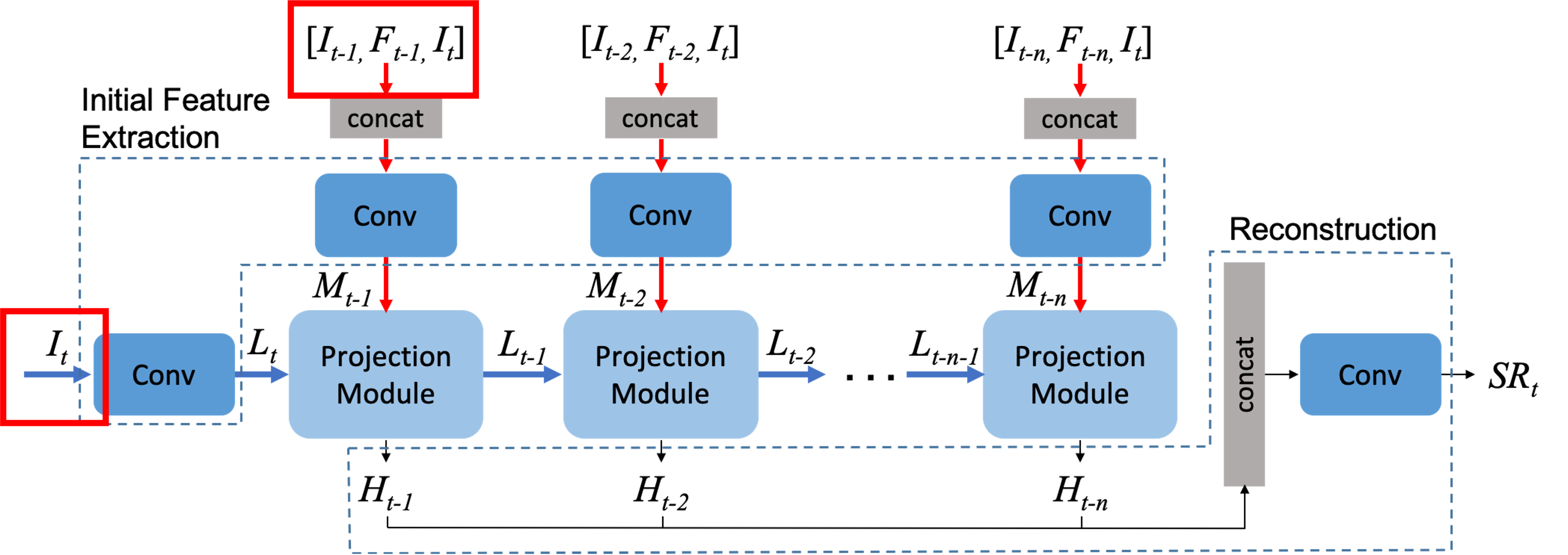
초기 추출 단계에서는 input이 총 3가지다.
It = target frame : SR을 뽑기 위한 대상이다.
It-1 = 사용자가 지정한 범위 내에 인접 frame :
Ft-1 = dense motion flow map : A에서 B로 가는 사이의 optical flow를 나타내는 것으로 생각된다. 이 것을 계산하는 함수는 라이브러리를 사용하는데 그 깃 허브에 들어가보면 예시 이미지가 optical flow를 나타낸다. target frame과 It-1 frame 사이의 누락된 세부 사항을 추출하도록 장려한다고 한다.
https://github.com/pathak22/pyflow/tree/master/examples
GitHub - pathak22/pyflow: Fast, accurate and easy to run dense optical flow with python wrapper
Fast, accurate and easy to run dense optical flow with python wrapper - GitHub - pathak22/pyflow: Fast, accurate and easy to run dense optical flow with python wrapper
github.com
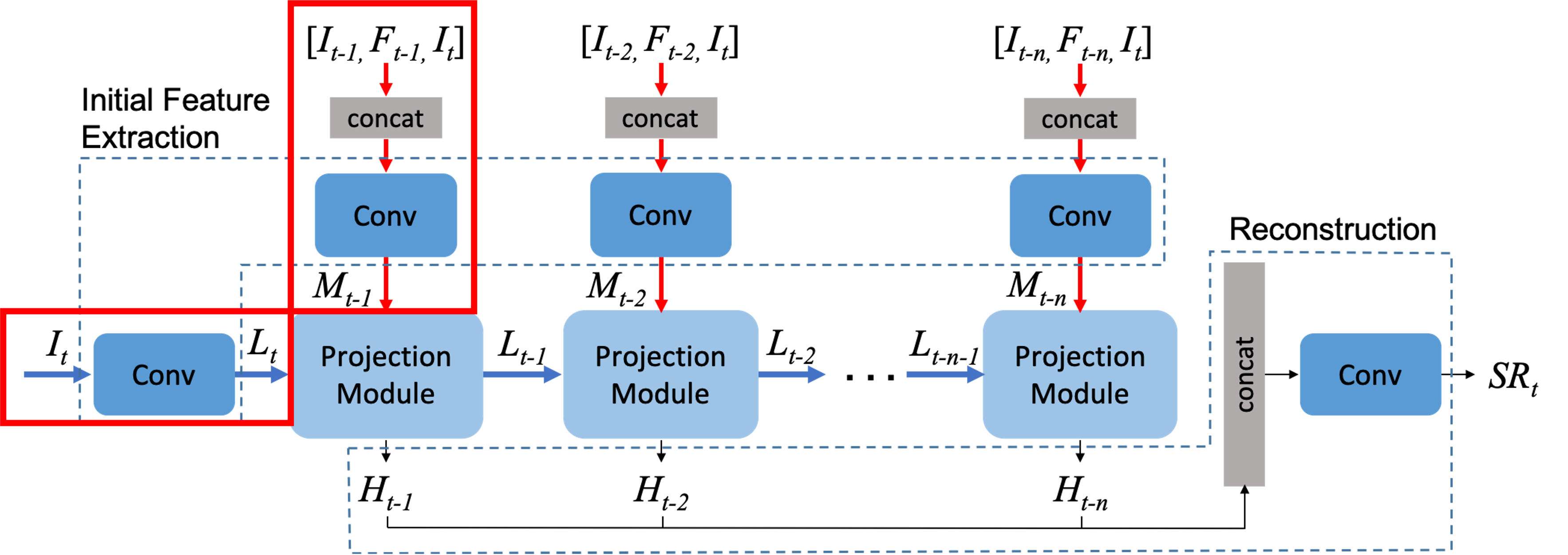
Target frame은 convolution 레이어를 거치며 LR feature tensor는 Lt에 mapping 되고 상단 3개의 input은 concat을 거치고 convolution되며 일명 neighbor feature tensor가 Mt-1에 맵핑된다.
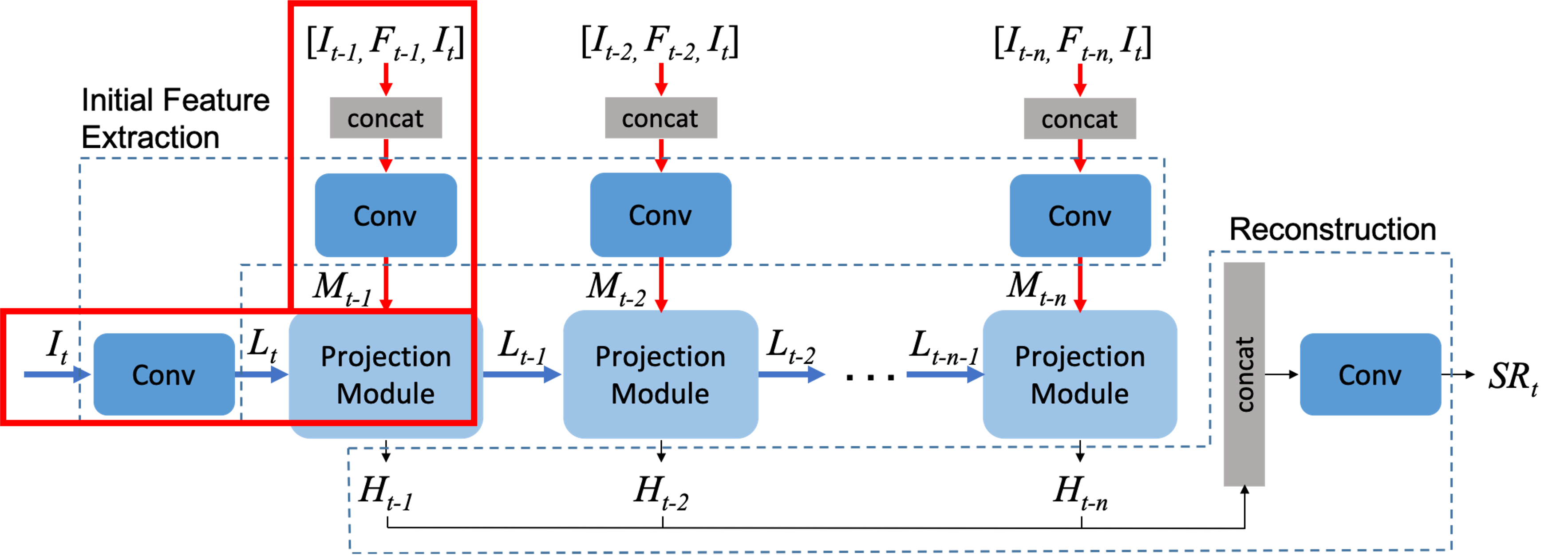
둘은 projection module에서 만난다.
Multiple Projection 단계
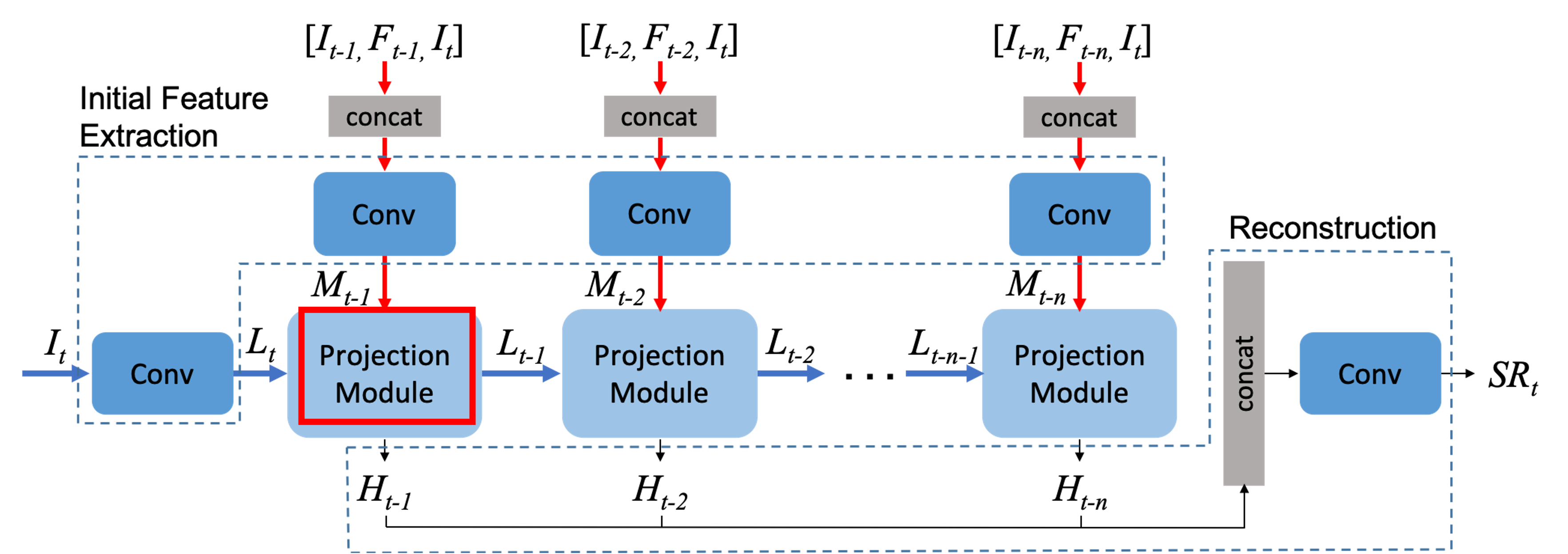
Projection module에서는 HR feature tensor Ht-1과 다음 단계로 넘겨줄 input Lt-1을 생성한다.
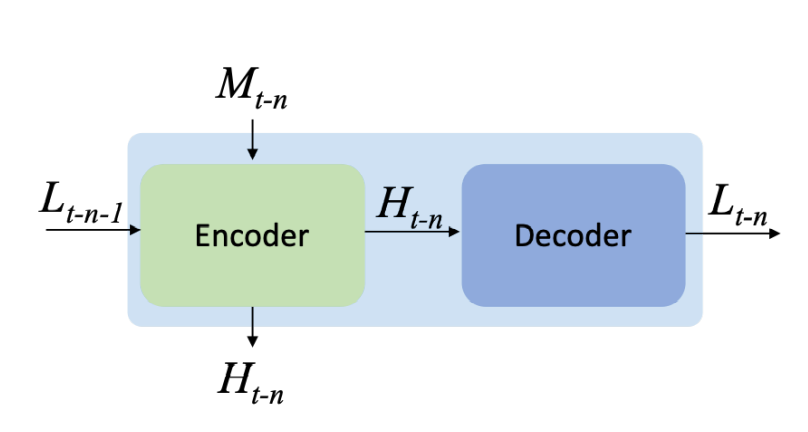
Projection module은 크게 Encoder와 Decoder 임무를 수행한다.
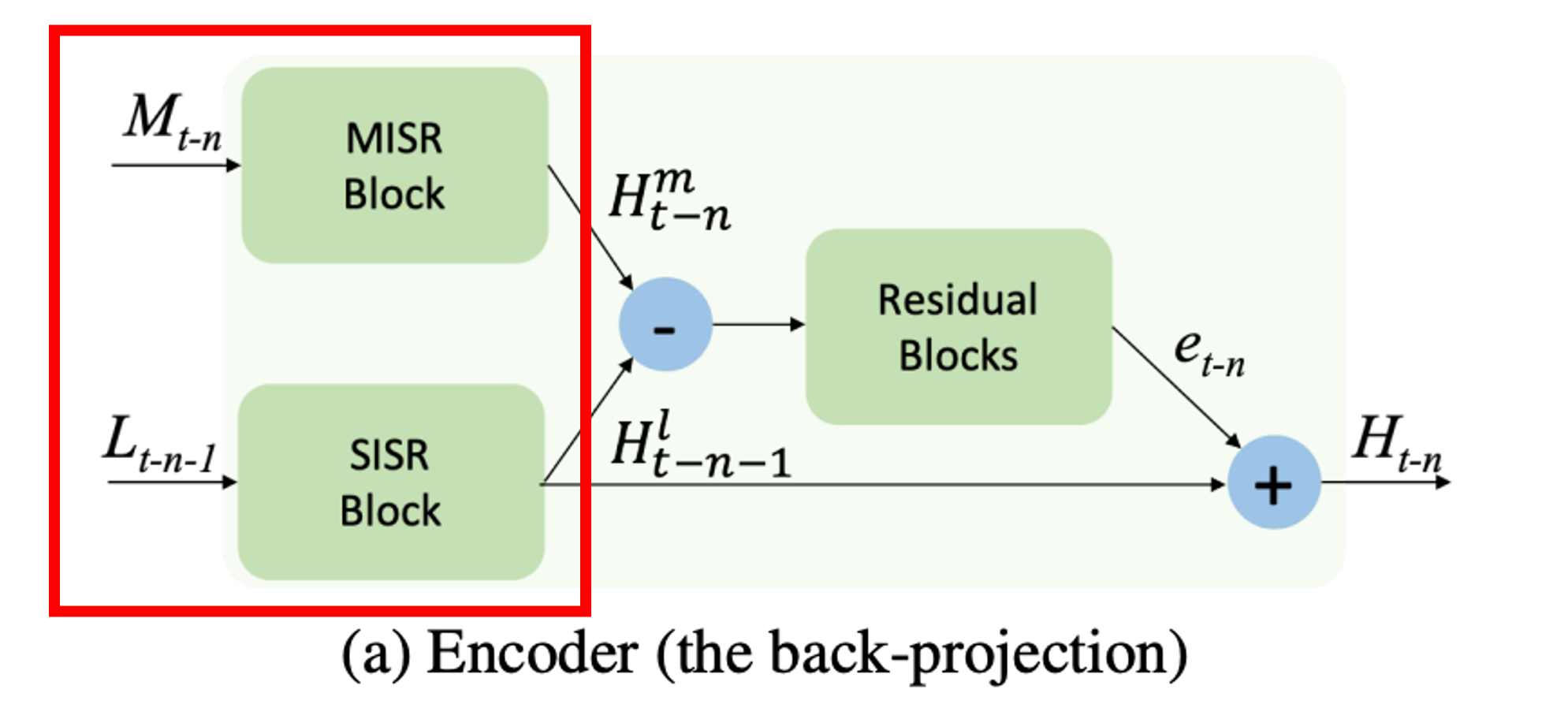
인코더에서는 MISR과 SISR이 각 데이터들을 맞이한다. SISR에서는 target frame에서 들어온 feature를 가지고 SR을 수행하고 MISR은 상단에서 target frame, dense motion flow map, 타겟 인접 프레임 이 3개가 concat되고 나온 feature를 upscale 및 warping한다.
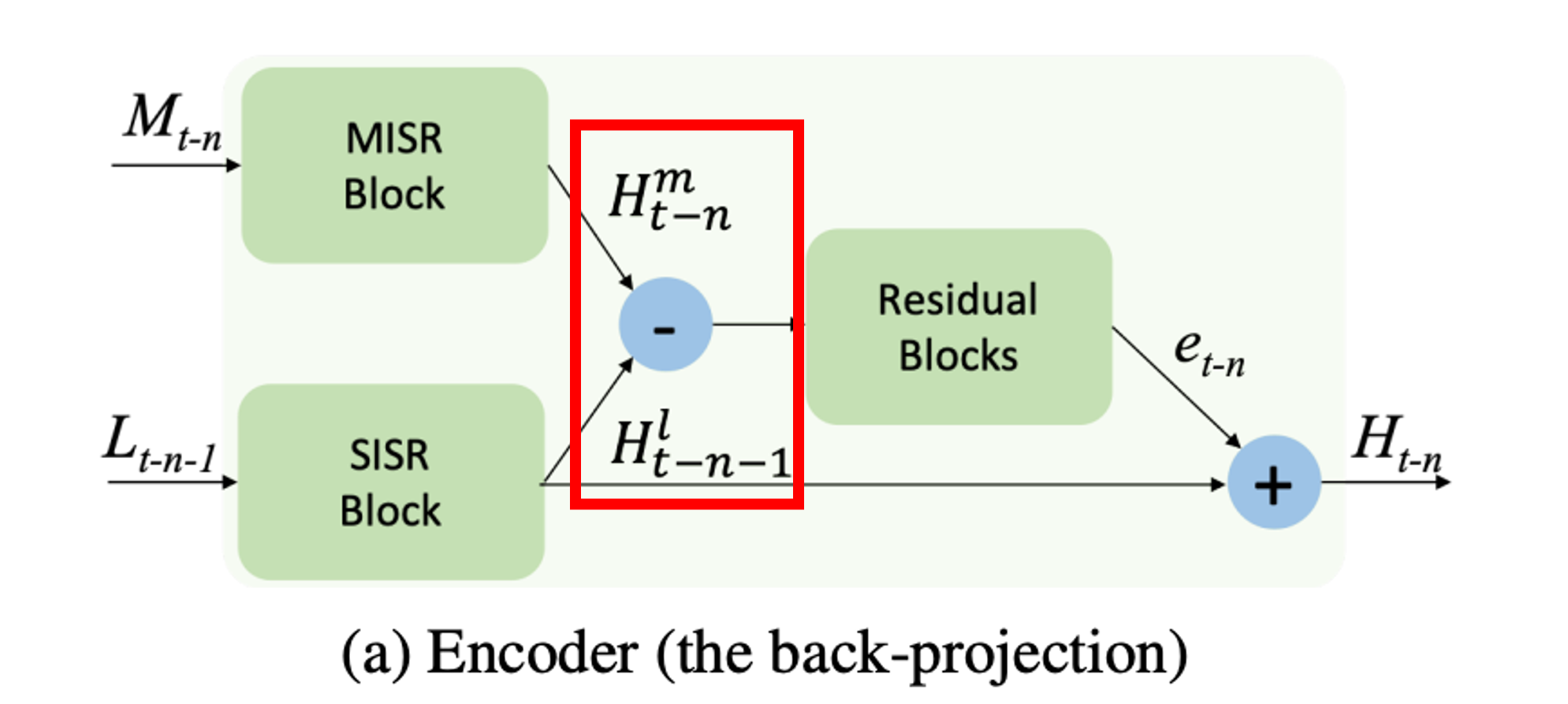
SISR과 MISR의 결과에서 빼기를 수행한다. 코드로도 단순하게 -를 진행
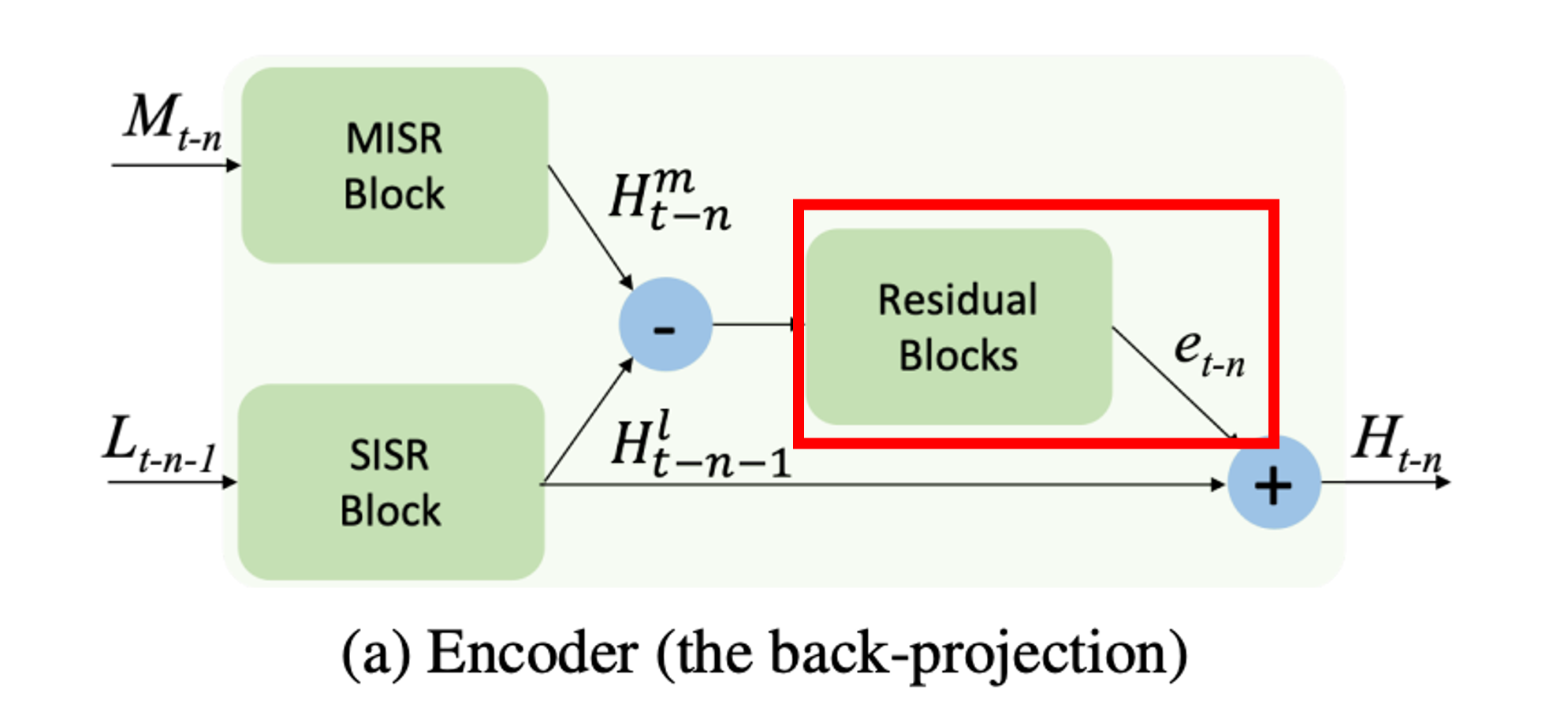
계산된 차를 가지고 et-n(feature)를 뽑아낸다.
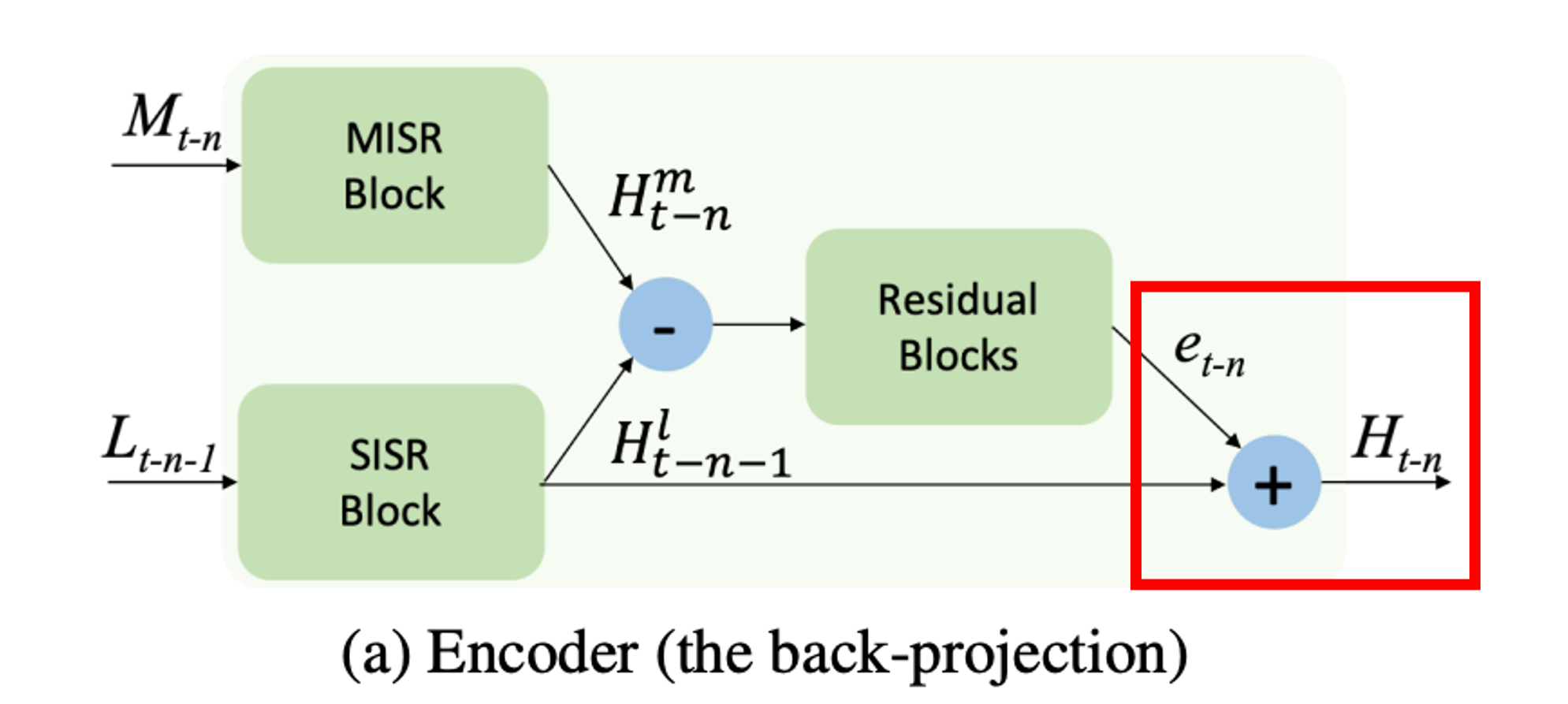
계산해서 나온 차와 SISR결과와 합을 하여 Ht-k를 만든다.
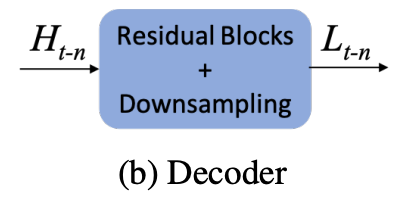
Decoder는 Ht-k를 다음 스텝에서 사용할 수 있게 donwsampling, resblock으로 feature를 다듬는 과정을 수행한다.
이 모델은 앞선 방법들을 사용하여 각각 프레임들이 target frame에서 누락된 세부 정보를 채우는 것이 목표다. 이 방법대로면 다른 프레임이 없거나 정적인 부분에서 MISR을 무시하고 SISR처럼 수행한다.
차이가 발생하지 않기 떄문에 차이를 계속 더해주어도 feature에 큰 변화가 없을 것으로 예상됨
Reconstruction 단계
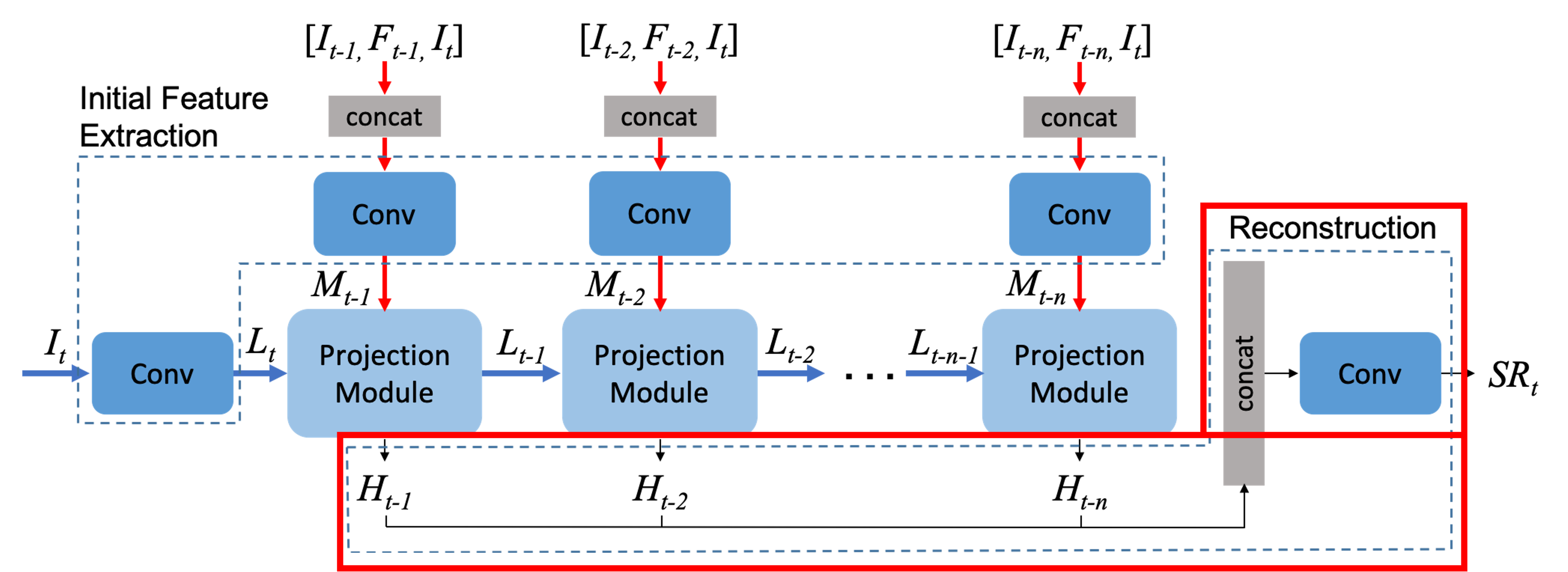
반복적인 작업 후 나온 HR feature tensor들은 concat되고 conv레이어를 거치면 SR이 완료된다.
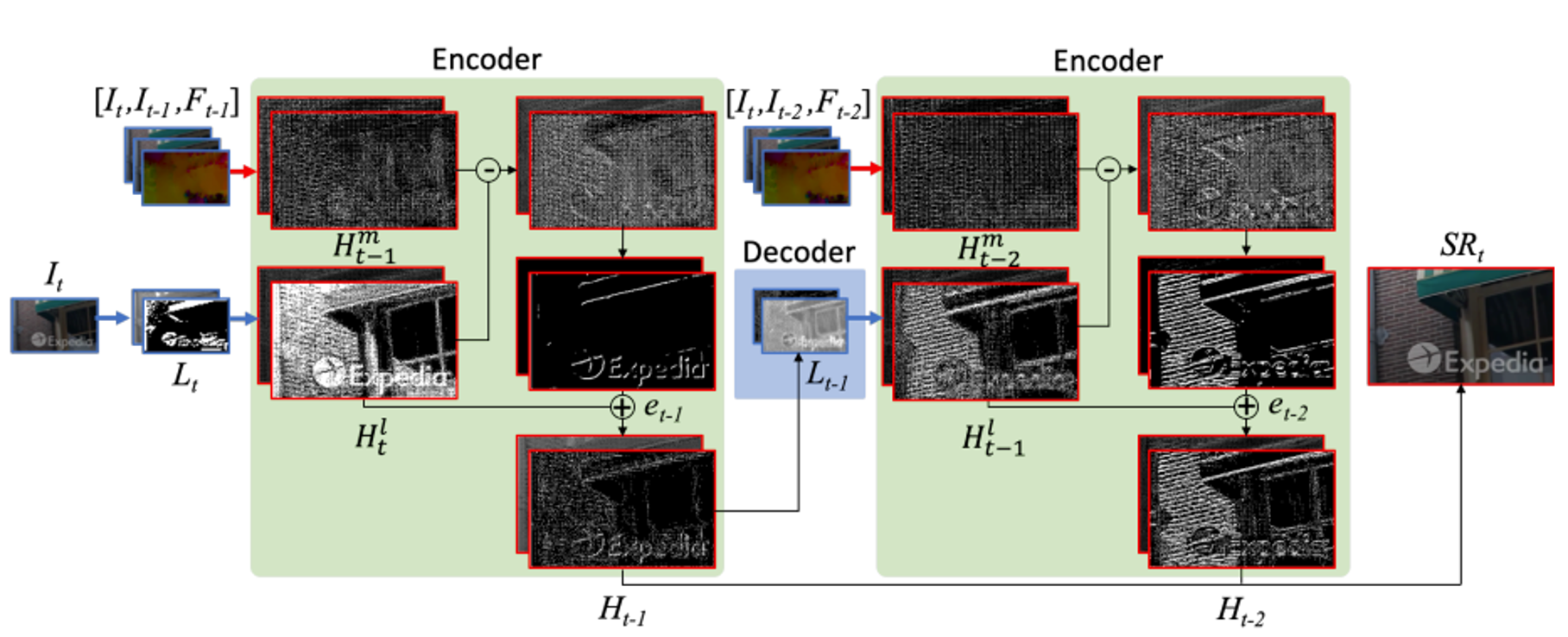
앞에서 말한 단계를 프레임이들어 갔을 때를 보여준다.
Target frame에서 feature와 sisr이 이루어지고 misr에서는 concat과 sr및 warping을 합니다. 둘은 차이를 구해서 특징을 뽑아내고 sisr결과와 합친다.
그렇게 나온 Ht-1은 각 지점마다 나오게되고 다음 단계로 넘어가는 path는 다시 다운 샘플링과 feature을 뽑고 넘기고 최종 결과로 가는 통로는 H들이 쌓이고 마지막에 SR이 나온다.
Training
Batch Size : 8
Patch Size : 64x64
Optimizer : Adam
Learning rate 처음 0.01로 시작, 절반 부터는 0.001로 진행
GPU : NVIDIA TITAN X GPU
Python : 3.5.2
PyTorch : 1.0 Dataset :
448x256 7-프레임으로 이루어진 64,612의 Vimeo-90k Data LR : Dataset을 bicubic을 이용해서 4배로 줄인다. Ratation, Flipping, Random cropping
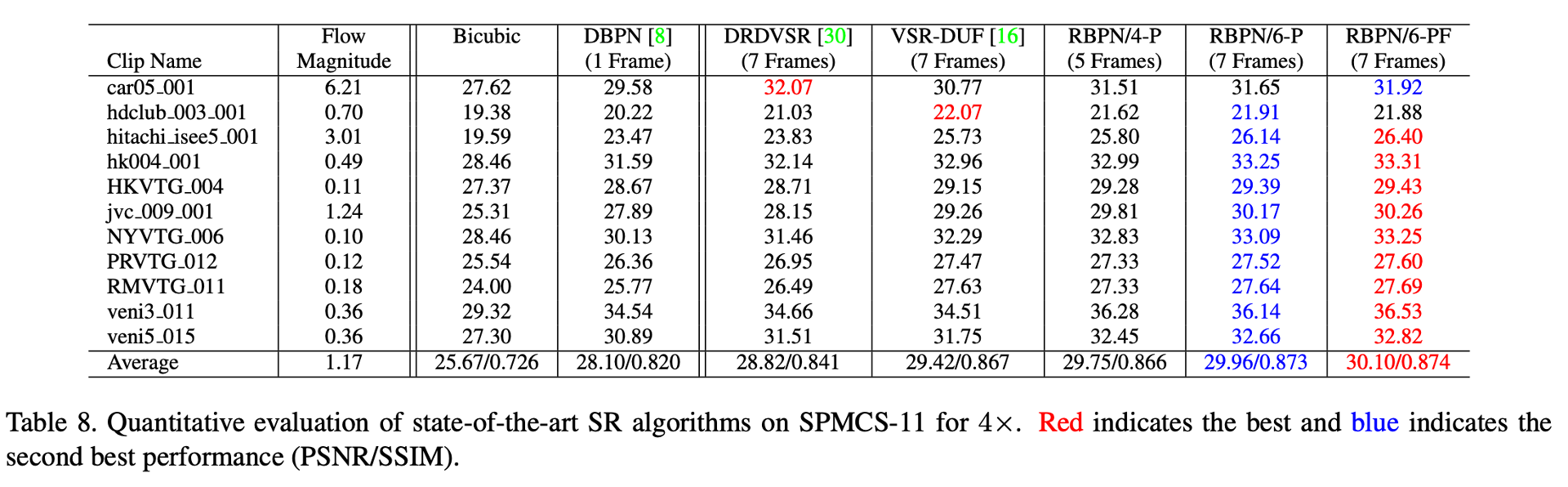
Result

Table 2: RBPN은 기존 방법들보다 좋지만 차이는 미미하다는 것을 나타댄다.
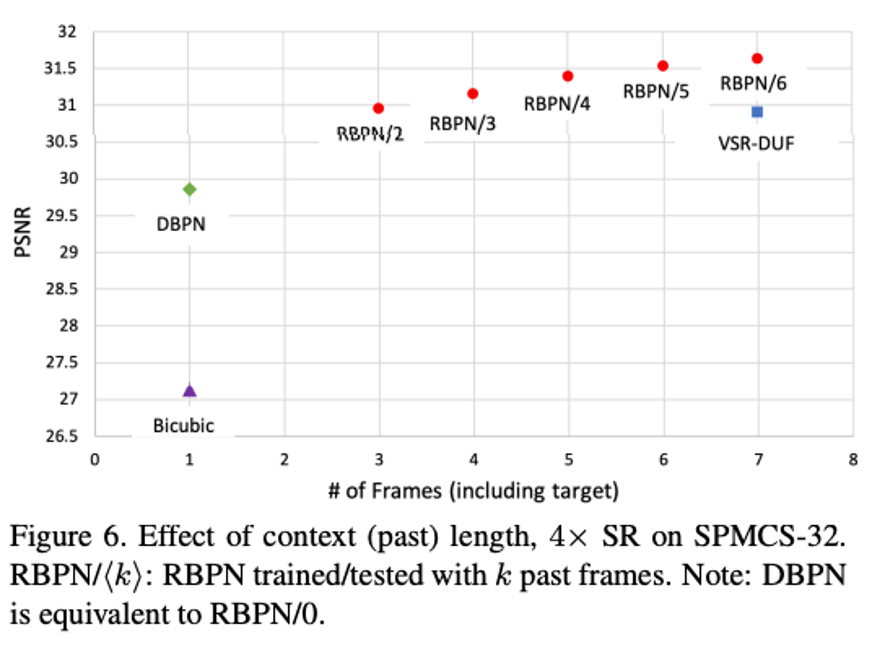
Figure 6 : 과거 프레임 개수가 미치는 영향의 대한 학습/테스트 결과이다. DBPN과 RBPN 0은 결과가 같다고 한다.

Figure 7 : VSR-DUF 6장의 프레임 사용. 보다 적은 프레임을 사용해도 RBPN/3프레임 사용이 더 좋은 복원력을 보여주는 그림, 프레임이 증가하면 더 좋은 결과를 낸다.

Table 4 : 과거를 가지고 학습/테스트한 결과보다 과거/미래를 같이 학습한 경우가 더 성능이 좋다고 한다. 하지만 PF(과거/미래)를 학습하고 P(과거를) 테스트하면 성능이 감소하지만 P(과거)를 학습하고 PF(과거/미래)를 테스트하면 성능은 거의 동일하게 유지된다.

Table 5 : 순서를 정한 과거 P, 무작위 순서 과거 PR과 비교한 테이블이다. 흥미롭게도 RBPN 성능은 순서 선택에 크게 영향을 받지 않는다고 논문의 저자는 주장한다.

Code
- 코드 설치
1. git clone https://github.com/alterzero/RBPN-PyTorch.git
GitHub - alterzero/RBPN-PyTorch: The project is an official implement of our CVPR2019 paper "Recurrent Back-Projection Network f
The project is an official implement of our CVPR2019 paper "Recurrent Back-Projection Network for Video Super-Resolution" - GitHub - alterzero/RBPN-PyTorch: The project is an official imp...
github.com
- Pyflow Build (dense motion flow를 구하기 위한 라이브러리)
1. cd RBPN-PyTorch/
2. cd pyflow/
3. python setup.py build_ext –I
4. cp pyflow*.so ..
-Pretrained Model
1. RBPN - Google Drive 접속
2. 구글 드라이브 속 weights 폴더 클릭
3. 모델들을 RBPN-PyTorch/weights에 저장
테스트 데이터
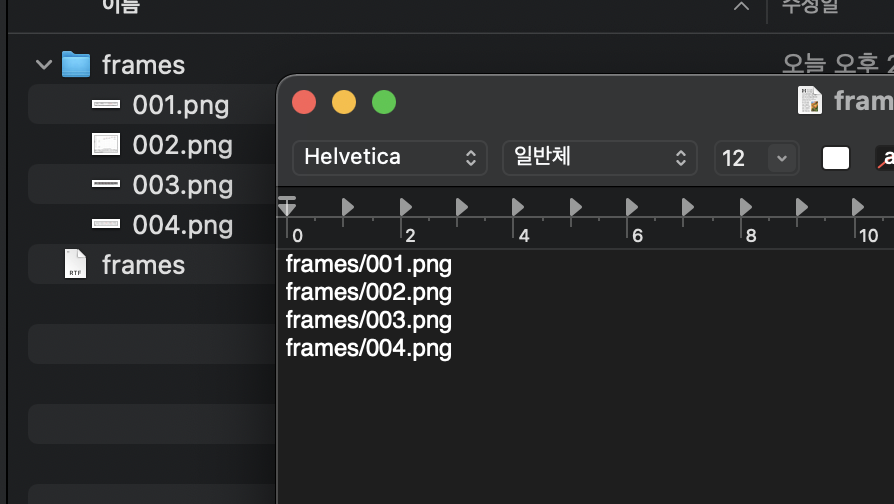
데이터는 다음과 같이 준비한다.
1. 폴더와 txt파일을 만든다.
2. 둘은 같은 이름으로 한다.
3. 폴더 속 파일 이름을 txt에 리스트로 작성해준다.
'다른 개발 > 기타' 카테고리의 다른 글
| Claude를 사용한 Mac OS App - 로또 당첨 조회 앱 (0) | 2025.01.16 |
|---|---|
| [Github] 오픈소스 기여하기, Contributor (0) | 2024.01.06 |
| [Web] Sign in with Apple 웹, 애플 로그인 간단하게 알아보기 html, js 사용 (0) | 2024.01.05 |
| [Open API] 카카오(다음) 주소 검색 API 사용 (0) | 2023.12.07 |
| [Node] FCM Topic(주제)을 이용한 Push Notification 메세지 전송 feat. mutable-content (0) | 2023.06.16 |



